![[LIBEVOLUTIONEVAL Teaser Image]](teaser.png)
![[Dataset Construction Process]](dataset_construction.png)
Main Results
Figure below illustrates the code completion performance (F1 score) of the StarCoder2, Mistral, and GPT-4o-Mini models. As libraries evolve, these code LLMs show significant variations in their ability to complete code correctly, indicating the need for version-aware context.
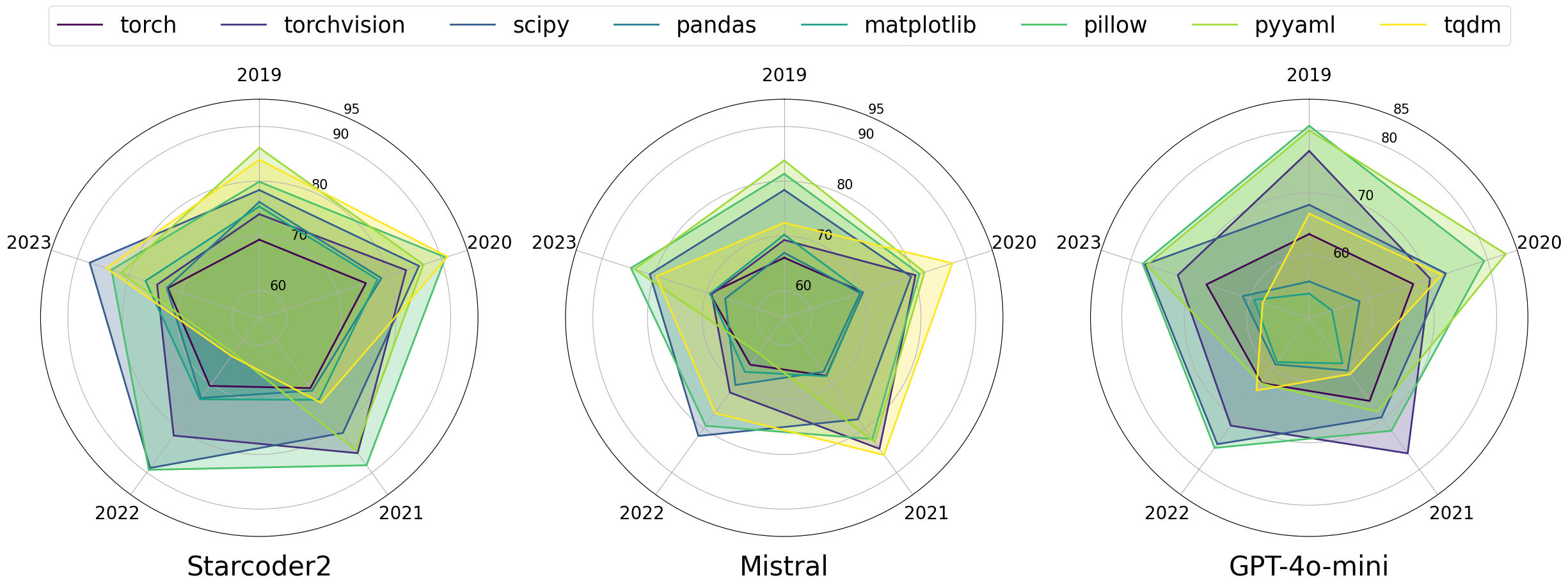
After examining overall trends from the polar plot, we present a more detailed breakdown of results (see table below) focusing on two representative libraries — PyTorch and Matplotlib. We evaluate three prompting strategies: In-File (not version-aware), Version-Aware, and Version-Aware RAG.
| Model | Completion Strategy | Context Setting | PyTorch | Matplotlib |
|---|---|---|---|---|
| Starcoder2-7B | Fill-in-the-Middle | In-File (Not Version-Aware) | 68.8 | 69.7 |
| + Version-Aware | 69.3 | 70.1 | ||
| + Version-Aware RAG | 73.3 | 75.4 | ||
| Mistral-7B | Left-Context Only | In-File (Not Version-Aware) | 65.8 | 60.18 |
| + Version-Aware | 66.04 | 61.2 | ||
| + Version-Aware RAG | 67.6 | 69.05 | ||
| GPT-4o-Mini | Instruction-based (w/ Example) | In-File (Not Version-Aware) | 64.3 | 52.5 |
| + Version-Aware | 64.78 | 53.1 | ||
| + Version-Aware RAG | 70.14 | 66.7 |
We observe that performance generally improves with additional version-related context or retrieval.
![[CodeSage Scaling]](codesage_scale.png)
![[StarCoder Scaling]](scaling_starcoder.png)
![[In-File vs RAG]](infile_rag.png)
![[Direct vs Indirect Completions]](direct_indirect.png)
![[Overall vs Deprecated]](overall_deprecated.png)
![[MRR Scores CodeSage/OpenAI Ada]](rag_em.png)